О Redis
2019-09-01
Я давно и успешно пользуюсь Redis, и другим рекомендую. Но всё никак про неё не писал. Исправляюсь.
Redis — это почти буквально «редиска» (которая на самом деле "radish"). И СУБД. Поэтому «она».

Redis — это in-memory СУБД типа ключ-значение. То есть она хранит все данные в оперативной памяти, и данные представлены в виде множества значений, каждое из которых можно получить по ключу.
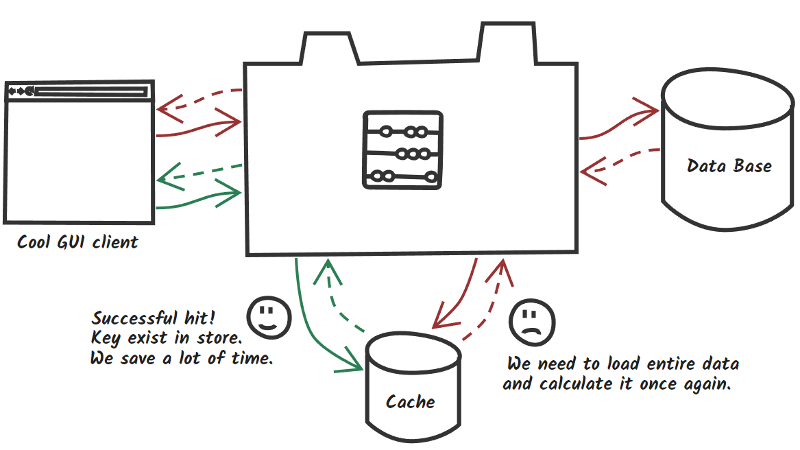
Хранить данные в памяти нужно в первую очередь для скорости. И такие СУБД в первую очередь используются для кэшей. Собственно, ближайшим «конкурентом» Redis является Memcached. В AWS managed инстансы их обоих даже создаются одним и тем же сервисом ElastiCache.
Раз уж это кэш,
то его и можно использовать как кэш.
Например, настроив Cachable в Spring.
Тогда результаты вызова почти любого метода будут сохраняться в кэш,
и повторые вызовы с теми же аргументами
будут возвращать результаты из кэша,
что, в данном случае, гораздо быстрее.
// этот метод приходится вызывать довольно часто
@Cacheable(cacheNames = ["entity-ids"], keyGenerator = "redisCacheKeyGenerator")
override fun getEntityIds(
entities: Collection<String>?,
entityTypes: Collection<String>?,
// и прочие другие фильтры...
): Collection<String> {
// довольно сложный запрос в БД по редко меняющимся данным...
}
Кэши в Spring управляются через CacheManager.
Для кэша в Redis есть своя реализация RedisCacheManager.
Время жизни записей в кэше — это, в данном случае, фича Redis.
Для каждой записи можно задать время жизни,
и она будет автоматически удалена через указанное время.
Каждая запись кэша в данном случае
будет связана с вызовом метода с определённым набором аргументов.
@Bean
open fun redisCacheManager(
@Qualifier("cacheRedis") redis: RedisOperations<Any, Any> // это подключение к Redis
): CacheManager {
val manager = RedisCacheManager(redis)
manager.cacheNames = cacheRedisNames().names // имена кэшей ("entity-ids") можно задать явно
manager.setUsePrefix(true) // добавлять префикс к ключам, чтобы отличать их от других ключей в том же Redis
manager.setDefaultExpiration(cacheExpiration) // время жизни по умолчанию
return manager
}
Здесь я захотел нарисовать кастомную сериализацию ключей кэша. Потому что дефолтная реализация вроде как не включает имя метода, что может привести к ненужным коллизиям.
@Bean
open fun redisCacheKeyGenerator(): KeyGenerator {
return KeyGenerator { target, method, params ->
val sb = StringBuilder()
sb.append(target.javaClass.name) // добавляем имя класса
sb.append(method.name) // и имя метода
for (obj in params) {
sb.append(obj?.toString() ?: "") // и все аргументы
}
sb.toString()
}
}
Для работы с Redis в Spring, по аналогии с другими БД,
используется RedisTemplate,
реализующий интерфейс RedisOperations.
Чаще всего используется RedisTemplate<String, String>,
то есть и ключи и значения являются строками.
Но здесь у нас кэш, и значением может быть любой объект,
поэтому RedisTemplate<Any, Any>.
@Bean
open fun cacheRedis(
serializer: Jackson2JsonRedisSerializer<Any> // сериализатор для значений
): RedisOperations<Any, Any> {
val template = RedisTemplate<Any, Any>()
template.connectionFactory = cacheRedisConnectionFactory() // как мы будем подключаться к Redis
template.keySerializer = StringRedisSerializer() // ключи у нас таки строки, наш генератор создаёт строки
template.hashKeySerializer = serializer // про hash поговорим попозже
template.valueSerializer = serializer // для значений используем специальный сериализатор
return template
}
Значения, которые сохраняются в кэш,
должны быть сериализованы.
По умолчанию используется обычная сериализация Java,
которая требует, чтобы объекты реализовывали
Serializable.
Но у нас всякие сущности вовсе не всегда так сериализуются,
но зато они вполне представимы в JSON.
Поэтому создаём кастомный сериализатор в JSON с помощью
Jackson.
@Bean
open fun jackson2JsonRedisSerializer(
@Qualifier("objectMapper") objectMapper: ObjectMapper // есть у нас уже всесистемный Jackson, который умеет сериализовывать все нужные классы
): Jackson2JsonRedisSerializer<Any> {
val jackson2JsonRedisSerializer = Jackson2JsonRedisSerializer(Any::class.java) // а это сериализатор, использующий Jackson
val mapper = objectMapper.copy()
mapper.disable(DeserializationFeature.FAIL_ON_IGNORED_PROPERTIES) // не падать, если при чтении встретилось свойство объекта, которое мы игнорируем
mapper.disable(DeserializationFeature.FAIL_ON_UNKNOWN_PROPERTIES) // не падать, если при чтении встретилось неизвестное свойство объекта
mapper.setSerializationInclusion(JsonInclude.Include.NON_NULL) // не пишем null значения, типа место экономим
mapper.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY) // писать все свойства объектов, а не только публичные
mapper.enableDefaultTyping(ObjectMapper.DefaultTyping.NON_FINAL) // добавлять в JSON информацию о конкретном Java типе, чтобы потом прочитать этот же тип
jackson2JsonRedisSerializer.setObjectMapper(mapper)
return jackson2JsonRedisSerializer
}
Для подключения к Redis обычно явно указывают хост, порт и номер БД. Но существует также полуофициальный стандарт на URL вида "redis://". Вот его «парсинг» я и реализовал.
@Bean
open fun cacheRedisConnectionFactory(): RedisConnectionFactory {
log.info("Cache Redis: $cacheUrl")
if (cacheUrl.scheme != "redis") {
throw IllegalArgumentException("$cacheUrl must be redis:// url")
}
val jedis = JedisConnectionFactory() // Java клиент к Redis называется Jedis
jedis.hostName = cacheUrl.host
jedis.port = if (cacheUrl.port == -1) 6379 else cacheUrl.port // порт по умолчанию 6379
jedis.database = cacheUrl.path?.split('/')?.getOrNull(1)?.toIntOrNull() ?: 0 // БД по умолчаню 0
return jedis
}
К Redis серверу подключаются по TCP, порт по умолчанию 6379. По этому TCP подключению клиент (синхронно) посылает команды и получает ответы. Так что тут тоже нужен пул коннекций. В Jedis пул есть.
При подключении можно указать номер БД. На самом деле в Redis может одновременно храниться несколько независимых наборов ключей. Они и называются базами данных и нумеруются с нуля. Обычно это редко используется, и по умолчанию вся работа происходит с набором ключей номер ноль. Но их там, на самом деле, создаётся с десяток (настраивается в конфигурации сервера). Для разных наборов данных можно выбрать разные номера БД, чтобы не мучаться с изобретением непересекающихся префиксов ключей.
Redis как кэш вполне быстр. Но только если ваш кэш находится в той же локальной сети или датацентре. Если же приложение у вас здесь, а кэш за океаном, всё становится значительно грустнее. Всё правильно, против физики не попрёшь. Round-trip по сети требует время. И, в случае большой сетевой задержки, реально может быть быстрее сходить в SQL базу, и получить много данных за один запрос, чем много раз опрашивать кэш. Кэш — это много round-trip, всегда.
Memcached — это прям тупо-тупо ключ и какое угодно значение. Для Memcached значение — это просто набор байт. А вот в Redis значения бывают некоторых разных интересных типов. И это прикольно.
Базовый тип данных в Redis называют String. На самом деле это любой набор байт. Длиной до 512 мегабайт. Можно непосредственно записывать и получать String по ключу. Можно инкрементировать и декрементировать значения, если в строке записано десятичное число, обычными ASCII цифрами, типа "123". А можно даже манипулировать отдельными битами этой «строки», что, как уверяет документация, позволяет хранить в Redis фильтры Блума.
В Redis есть списки (List). Под одним ключом можно хранить не одну строку, а список строк. Можно добавлять элементы в начало, конец, в произвольную позицию в списке. Можно читать элементы в начале, конце, в произвольной позиции в списке. Можно читать срез списка. Можно обрезать список. Для всего этого есть операции.
В Redis есть множества (Set). Это как списки, но они неупорядочены и хранят только уникальные значения. Можно находить пересечения, объединения и разность множеств. То есть реально взять и прочитать несколько ключей и пересечь прочитанные множества, и даже сохранить результат в другой ключ. Всё одной операцией.
Redis — единственная известная мне БД,
где в документации указана сложность каждой операции.
Пересечение множеств — это O(N*M), где N — это количество элементов в самом маленьком множестве,
а M — количество пересекаемых множеств.
Логично.
Получение значения по ключу (GET) — это O(1).
Правильно,
у нас же key-value БД,
это вроде как большая хэш таблица.
Получение одной записи должно быть константным,
иначе это плохая хэш таблица.
А вот перечисление всех ключей (KEYS) — это уже O(N).
Что тоже логично,
нужно же перебрать все имеющиеся ключи.
Но это также значит,
что если вам нужно выбрать несколько связанных значений,
нельзя искать их, перебирая ключи.
Решение: использовать Set. Заведите отдельную запись, с отдельным известным ключом, типа Set, которая будет «каталогом» ваших связанных записей. Когда добавляете запись, делайте ещё SADD в запись-каталог. Да, при записи будет на одну операцию больше. Зато потом, чтобы прочитать весь набор нужных записей, вы читаете (SMEMBERS) ваш «каталог», а потом читаете каждую нужную запись. Уже нет нужды перебирать все ключи в БД.
Собственно, такое комбинирование, создание дополнительные записей, ссылающихся на другие записи для их быстрого поиска, — это типичный подход при хранении сложных структур данных в key-value СУБД. Больше разных промежуточных ключей, чтобы искать другие ключи более эффективно. Ведь получить значение по ключу — это очень быстро.

В Redis есть хэши (Hash).
Если само key-value хранилище является мапой (ассоциативным массивом, словарём, хэш таблицей)
ключей в значение,
но в Redis само значение тоже может быть мапой.
Получается мапа мапы.
В принципе, если у вас только плоские объекты,
и часто нужно получать или изменять только часть их свойств,
то вполне можно хранить их в хэшах Redis,
безо всякой дополнительной сериализации.
В Redis есть упорядоченные множества (Sorted set). Они ведут себя как обычные множества, хранят только уникальные значения, но дополнительно упорядочены по score. Score — это вещественное число, связанное с каждым сохранённым значением. В Sorted set удобно хранить, например, облако тегов с весами.
А я использовал Sorted set чтобы хранить последние уникальные детекции. Допустим у нас есть какие-то сенсоры, которые детектируют, когда мимо них проносят некоторые теги. Каждому сенсору назначим ключ и заведём запись типа Sorted set в Redis. В качестве значения множества будем указывать обнаруженный тег. А в качестве score — таймстамп (число секунд с начала эпохи). Теперь одной операцией ZREVRANGEBYSCORE можно получить все теги, обнаруженные данным сенсором за последние пять, десять, пятнадцать минут. Это часто именно то, что нужно показывать в так называемых real-time данных. При этом размер записи в Redis определяется лишь количеством уникальных тегов, но не тем, как долго этот сенсор работает. Весьма удобно.
В Redis есть и парочка других, более экзотических типов данных. Но я вам про них ничего не скажу, ибо не использовал.
Хоть Redis и хранит все данные в памяти, периодически он скидывает снапшоты на диск. Так что, при корректных шатдаунах, он вполне персистентен и будет надёжно хранить ваши данные.
Redis поддерживает master-slave репликацию. Для надёжности и для масштабирования по чтению. Когда вы подымаете Redis в ElastiCache, обычно и создаётся сразу парочка слейвов.
Redis может переназначать мастера, если оригинальный мастер сдох. Этим high availability занимается отдельная штука под названием Sentinel.
Ещё существует и Redis Cluster. Там есть и шарды, то есть можно хранить наборы данных, которые не помещаются в память одной машины.
Хоть оно вроде возможно, тем не менее я не слышал, чтобы Redis использовали как средство хранения конфигурации в распределённых системах, вместо ZooKeeper или Consul. Не знаю, почему.
А ещё в Redis есть Pub/Sub. Публикация-подписка. Поначалу я думал, что это возможность подписаться на изменения каких-нибудь ключей, и получать уведомления, когда значения ключей меняются. Оказалось, нет. Это просто возможность одному множеству клиентов, подключенных к серверу, подписываться на сообщения в некоемом топике. А другому множеству клиентов публиковать сообщения в топик. Произвольные бинарные сообщения. Просто ещё одна фича Redis, совершенно ортогональная нашим ключам-значениям.
Не то, чтобы это был полноценный брокер сообщений. Тут нет многих возможностей, предоставляемых более полноценными очередями сообщений. Но, если у вас уже есть Redis, и вам просто нужно что-то передавать из одного компонента в другой, можно воспользоваться и этим Pub/Sub, нечего плодить ещё сущностей.
А ещё в Redis есть зачатки транзакций.
А ещё в Redis можно выполнять на серверной стороне код на Lua. Становится понятно, откуда у Tarantool ноги растут.

Пользуйтесь Redis. Он простой, быстрый и предсказуемый. Его можно использовать как просто внешний сетевой кэш, как быстрое хранилище сложных оперативных данных, как простой брокер для обмена сообщениями, и как много чего ещё.