Об ECS
2021-05-07
Про ECS, который сервис для развёртывания и управления докер контейнерами в AWS, я уже как-то писал. За прошедшие пару лет ECS не умер, не был полностью вытеснен EKS, который со вкусом Kubernetes, а даже стал лучше и пригожее.
ECS — это Elastic Container Service. Типичное название для Амазона. Да, про контейнеры.
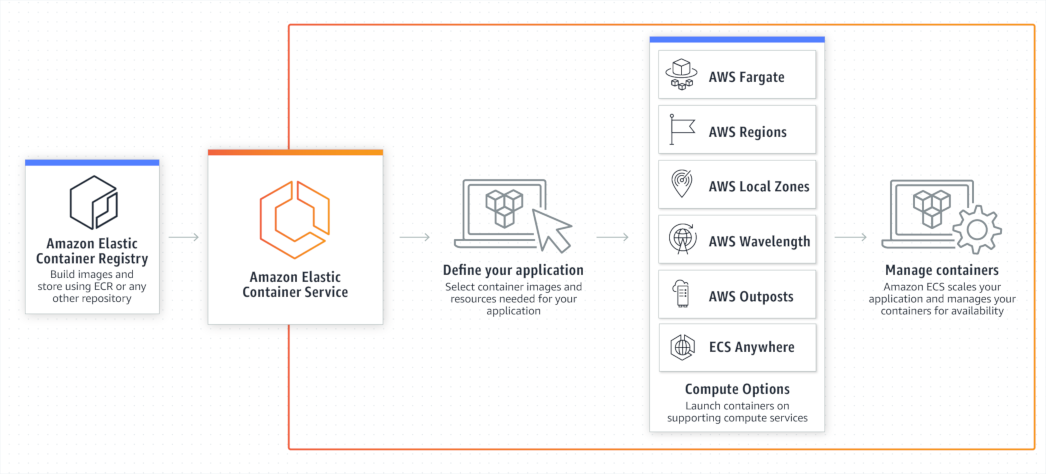
Начинается ECS с создания ECS кластера.
aws_ecs_cluster
в терминах Terraform.
У кластера никаких особых свойств, кроме его имени, нет.
Вообще, если всё настраивать Terraformом, то придётся разобраться во всех этих ресурсах, а их будет много.
Задача кластера — запускать таски (Tasks). Таски — это один или несколько Docker контейнеров, запускаемых вместе. Аналог подов в Kubernetes.
Таски возникают из описаний: Task definitions.
aws_ecs_task_definition в Терраформе.
Здесь,
для каждого контейнера таска,
задаётся Docker образ,
требования по памяти (обязательно) и CPU (в некоторых случаях необязательно),
режим работы сети и пробрасываемые порты,
подключаемые тома (если нужно),
куда будут записываться логи (то бишь, stdout),
IAM роль,
от имени которой будут работать контейнеры,
ну и переменные окружения.
Помним же о The Twelve-Factor App? Всё должно настраиваться через переменные окружения.
Docker образы хранятся в ECR — Elastic Container Registry. Хоть он и очень тесно взаимодействует с ECS, это вполне самостоятельный сервис. Полноценный Docker Registry, который можно использовать и напрямую. Единственный существенный нюанс: пароли доступа в ECR — временные. Их нужно генерить через AWS CLI. И они действуют не более 12 часов.
ECS таски можно запускать поодиночке. Так поступает, например, другой амазоновый сервис Elastic Beanstalk. Либо можно запускать таску по таймеру. Но сама по себе таска — это немасштабируемый и слабо контролируемый ресурс. Она может быть только запущена или остановлена, если сама не остановится раньше.
Гораздо интереснее ECS сервисы.
aws_ecs_service в Терраформе.
Сервис управляет развёртыванием, масштабированием и обновлением тасков.
Где и сколько тасков поднять.
В каком порядке их подымать при обновлении,
чтобы сервис всегда был доступен.
Где именно эти таски запускать.
Где вообще ECS запускает контейнеры? Есть два способа (на самом деле больше). Либо вы запускаете свои собственные EC2 инстансы, в которых установлен Docker и ECS агент. Либо вы используете AWS Fargate.
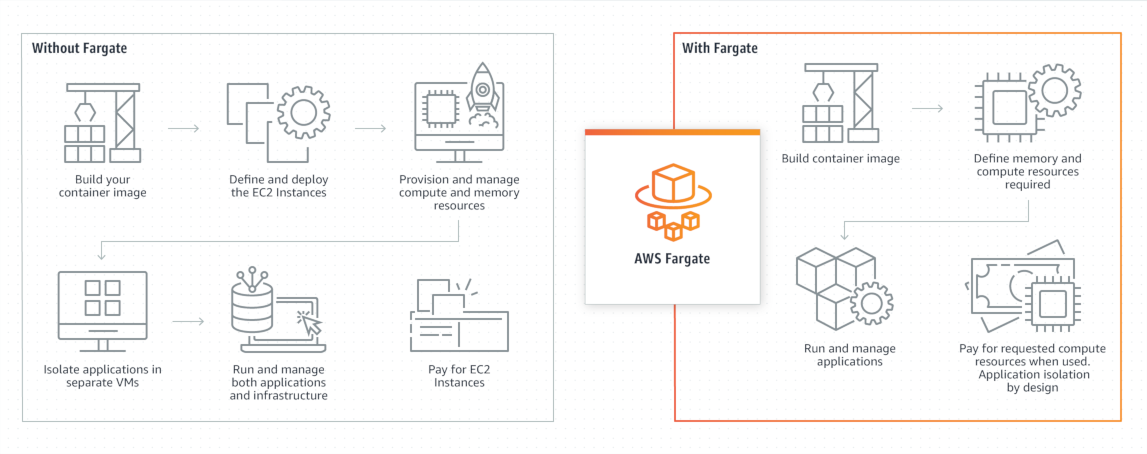
Fargate — это великая магия. Вы говорите, сколько памяти и CPU нужно вашим контейнерам (точнее, таске), и оно магическим образом запускается где-то там. Прекрасно, красиво, но дорого. В несколько раз дороже, чем аналогичные EC2 инстансы.
Fargate имеет смысл использовать, если ваши ECS таски работают не постоянно. И вы не хотите заморачиваться с масштабированием EC2 инстансов. Например, на одном из проектов мы сделали так, что из десятков сервисов постоянно запущен только один. А остальные остановлены, пока в приложение никто не заходит. А вот когда кто-то заходит, этот главный сервис «будит» всех остальных, и через минуты полторы приложение полностью развёрнуто, со всей функциональностью. Для демо окружения — самое то.
Иначе же выгоднее заморочиться с EC2.
Точнее, с Auto Scaling Group.
aws_autoscaling_group в Терраформе.
Auto Scaling Group — это штука,
которая создаёт EC2 инстансы согласно Launch Configuration
(aws_launch_configuration,
устарели)
или Launch Template
(aws_launch_template).
В конфигурации или шаблоне описано:
EC2 инстансы какого типа создавать,
из какого образа,
с какими параметрами,
и прочее.
Для работы с ECS уже есть заранее приготовленные образы
Amazon Linux.
Auto Scaling Group создаёт нужное количество инстансов
согласно некоторым правилам.
Раньше вам самим приходилось заботиться о том, чтобы EC2 инстансов в вашем ECS кластере было достаточно, чтобы запустить все нужные таски. И даже чуть больше на случай редеплоя. Либо руками задавать размер Auto Scaling Group. Либо пытаться прикрутить умные правила, основываясь, например, на потреблении памяти.
Теперь же в ECS появились Capacity Providers.
aws_ecs_capacity_provider в Терраформе.
Эта штука следит за размером вашего ECS кластера.
Она подключается к Auto Scaling Group,
и добавляет ещё EC2 инстансов, если нужно развернуть больше тасков.
Или прибивает лишние EC2 инстансы,
если на них никаких тасков не запущено.
А ECS сервисы теперь разворачиваются
именно используя Capacity Provider.
В особо хитрых случаях можно даже задействовать несколько провайдеров.
Работа Capacity Provider довольно мудрёна. Но оно работает. И работает правильно. Так что теперь можно без особых проблем добиться того, чтобы EC2 инстансов под ECS кластер было запущено ровно столько, сколько нужно. Можно жить и без Fargate.
Сами Auto Scaling Group тоже поумнели. Теперь группу можно заставить создавать инстансы разного типа. Для ECS это может быть удобно, если у вас есть таски с разными требованиями, например, к памяти. Если разные таски размещать на разных инстансах соответствующего размера, можно избежать излишнего расходования ресурсов, когда у вас половина памяти инстанса ничем не занята. Capacity Provider такие хитрости понимает и умеет (если верить документации).
Есть ещё один важный ресурс,
замешанный в работе ECS.
ELB — Elastic Load Balancing.
aws_lb в Терраформе.
Лоад балансер, балансировщик нагрузки.
Как и положено, лоад балансер балансирует входящий сетевой трафик
между несколькими бэкенд серверами: EC2 инстансами или IP адресами.
В ECS лоад балансер связан с сервисом. Сервис сообщает балансеру, где расположены его таски, и куда направлять трафик. А балансер сообщает сервису, живы ли они, согласно настроенным health checks. Важно, что тут именно ECS сервис общается с балансером. А то ведь ещё Auto Scaling Group тоже может им рулить, а в случае использования балансера с ECS такого не надо.
Elastic Load Balancing у нас есть нескольких типов. Опустим Classic Load Balancer, нынче для нового развёртывания он вам не понадобится. Опустим Gateway Load Balancer, это экзотическая разновидность для балансировки трафика к сторонним сервисам. Остаётся ещё два.
Network Load Balancer
работает на четвёртом уровне модели OSI,
то есть, балансирует TCP или UDP.
Он умеет слушать
(aws_lb_listener)
определённый TCP или UDP порт,
и перенаправлять/балансировать трафик на TCP/UDP порт вашего сервиса,
то, что называется Target Group
(aws_lb_target_group).
Опциально он может «терминировать» TLS подключения.
Здоровье вашего сервиса проверяется TCP или HTTP запросами.
Чтобы запрятать за Network Load Balancer несколько ваших микросервисов, придётся для каждого выделить отдельный порт, отдельный listener и отдельную target group. Потому что этот балансер умеет различать трафик только по портам. Этого достаточно для доступа к сервисам изнутри AWS. Но для внешнего доступа по единственному HTTPS/443 порту уже маловато. Поэтому Network Load Balancer прячут за API Gateway, особенно, если у вас уже есть API Gateway. Если балансер живёт в VPC, то для доступа из API Gateway вам понадобится VPC link.
Application Load Balancer
работает на седьмом уровне модели OSI.
Он умеет HTTP (и HTTPS).
Кроме listener и target group тут можно задать
listener rules
(aws_lb_listener_rule).
Помимо перенаправления трафика на target group,
можно осуществлять аутентификацию пользователя
или формировать статический ответ (что полезно, например, для CORS).
Можно выбирать target group,
а значит, и конкретный сервис,
по HTTP заголовкам, пути в URL, query в URL.
При наличии Application Load Balancer вам, вполне возможно, уже не нужен API Gateway. Теперь вы вполне можете спрятать все микросервисы за единственной публичной HTTPS/443 точкой входа. И маршрутизировать запросы на разные target group по довольно гибким правилам. Однако, помните, эти балансировщики всё же менее гибки, чем обычный Nginx. Скажем, они не умеют перезаписывать URL запроса.
В настройках лоадбалансера есть интересный параметр cross zone load balancing. Как вы помните, в каждом регионе AWS есть availability zones, зоны доступности. Балансер может перенаправлять трафик, то есть иметь свой ENI (Elastic Network Interface), в нескольких availability zones. Входящий трафик распределяется, по умолчанию случайно и равномерно, между всеми зонами, где у балансера есть интерфейсы. С другой стороны, EC2 инстансы в ECS кластере тоже могут быть запущены в разных availability zones. В зависимости от настроек Auto Scaling Group. И, если вы специально не озаботитесь разместить по таске ECS сервиса в каждой зоне, вполне может так оказаться, что в какой-то зоне не окажется вашего сервиса. В такой ситуации вам нужно включить cross zone load balancing, чтобы ENI балансера из одной availability zone мог бы обращаться к порту ECS сервиса в любой другой availability zone. Иначе могут быть странные задержки и потери трафика. Для Application Load Balancer cross zone load balancing по умолчанию включен, а вот для Network Load Balancer — выключен.
А теперь, повторим.

В ECS вы заводите кластеры. В кластере запускаются таски, по определению в Task Definition, где, помимо прочего, указан Docker образ, который запускать.
Для постоянно запущенных сервисов удобно создавать ECS service. Он сам создаёт таски для запуска своих экземпляров. И занимается редеплоем своих новых версий (новых версий Task Definition).
Таски запускаются на EC2 инстансах (или в Fargate). На этих инстансах запущен Docker и ECS агент. Для этого есть уже готовые AMI образы Amazon Linux. Агент подключается к ECS кластеру и так получает указания, что там в Docker запускать.
Количеством и типом EC2 инстансов управляет Auto Scaling Group. Инстансы создаются по Launch template (или Launch configuration). В ECS есть Capacity Provider, который управляет Auto Scaling Group, чтобы всегда было достаточно инстансов для запуска необходимых задач. В ECS сервисе нужно указать, каким Capacity Provider пользоваться для размещения тасков.
Кстати, на один ECS кластер вполне можно повесить несколько Capacity Provider и несколько Auto Scaling Group. И размещать ваши сервисы/таски по разным хитрым правилам.
Сетевой трафик на сервисы направляет Load Balancer. У него есть фронтенд часть — Listener, где указано, какой протокол на каком порту слушать, и TLS сертификат, если надо. И бэкенд часть — Target Group, которая следит за всеми тасками сервиса и их здоровьем.
Network Load Balancer умеет только TCP или UDP. Хотя heath checks может делать по HTTP. Application Load Balancer умеет HTTP/HTTPS. В нём можно задач сложные правила направления трафика, и много чего другого.
И напоследок. Если есть возможность не использовать Elastic Beanstalk, не используйте. Хоть снаружи этот сервис и пытается казаться простым и дружелюбным, под капотом там те же Auto Scaling Group, Load Balancer и наш ECS. Когда возникнет необходимость в этом разобраться и тонко настроить, всё равно окажется, что проще работать с ECS напрямую.