On DynamoDB
2025-07-02
We're in the clouds. How to get a database in a cloud?
You may run a usual virtual machine, and install PostgreSQL there. It will work. Especially if you need not just a usual PostgreSQL, but some rare DB beast which is not supported everywhere yet. You have to set up your own cluster of something exotic this way.
You may get the same PostgreSQL as a managed resource. In Amazon cloud, it's called RDS (Relational Database Service). Technically it's the same VM, however, a bit more expensive. But the DBMS setup, updates, backups, monitoring are no longer your responsibility, the cloud takes care of them. Specially educated cyberminions, configurable via a cloud console. It's really a great deal. It's actually useful. You may run many popular relational DBMS in this way: MySQL, PostgreSQL, Oracle, MS SQL Server. And even a couple of popular caches: Memcached and Redis (and Valkey).

And also we have cloud-only DBs. They live somewhere in the clouds. They are multitenant — the shared cloud resources are distributed between many clients. So, you can't say the DBMS is run on a virtual machine. It runs somewhere there, in the cloud.
As such DBMSes are scaled distributed systems, they are usually non-relational. NoSQL. But there are exceptions, DMBSes which look like SQL, but actually are not truly SQL.
Amazon has Redshift. It's a thing for analytics. A so-called Data Warehouse. You load your data there, and then perform SQL queries over the data. Slow. Expensive.
Also, Amazon has Aurora. It uses MySQL or PostgreSQL (your choice) wire protocols. But it's fully cloud-based. Currently, Amazon suggests using Aurora instead of regular RDS instances.
Back to NoSQL. Azure, Microsoft cloud, has wonderful Cosmos DB. It has a super-duper cool distributed transactional layer at its base. And you can use different data models above it, and different wire protocols. You can use it as simple key-value storage, with the interface similar to another Azure NoSQL database called Table. You can use the SQL API, where you store JSON documents and make SQL-like queries. You can use the MongoDB wire protocol and get document storage. You can use the Cassandra wire protocol and get columnar storage. And you can store graphs and access the database using standard graph APIs.
All these multi-layer multi-model concept of Cosmos DB looks similar to FoundationDB. Its coolness level is the same. And you can freely run it on your own hardware.
![]()
Let's dive into Amazon DynamoDB. Looks like it's one of the oldest cloud NoSQL solutions. Looks like DynamoDB always existed in AWS. Initially it was just a key-value storage, but then more features were added.
The data model of DynamoDB looks similar to Cassandra's. That Cassandra which is accessible with CQL.
There are Tables — uniquely named entities within the AWS account. A Table is the access control and speed limit unit.
A record in the Table is called an Item. Each Item is identified by a primary key. The primary key can consist of two parts.
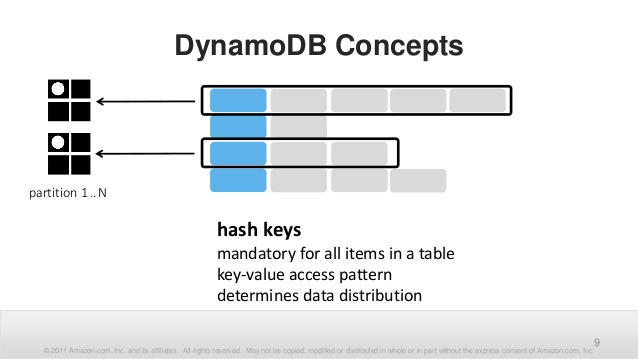
The first part is mandatory — the hash key. It's some primitive value (string, number, blob) whose hash is calculated. This is the partition key. The hash defines the partition where the data are stored. A partition is a physical entity with physically limited abilities. So, you need to choose a partition key with enough unique values. As it defines the maximum achievable physical performance of operations over the Table.
The hash key, its concrete value, no ranges or less-more conditions, must be defined both in write and read operations. It brings some restrictions. You must know the key values or an algorithm to derive them. There is no effective way to know the set of already existing keys. In the worst case, you need to invent some pseudo keys, just to create enough different partitions.
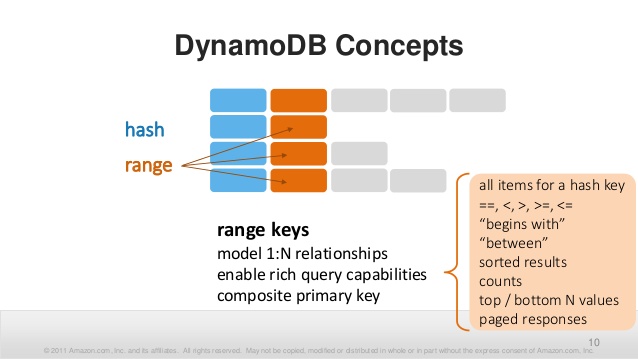
The second part of the primary key, optional, is the sort key. It's also a primitive value. Here, more sophisticated queries are possible: greater than, less than, and between. Sorting is possible by this and only this field. Sorting is possible in both directions.
That's all for keys. It's only possible to select Items by these keys. And the partition key is required. However, there are secondary indexes where you can define other partition and sort keys over the same dataset. But technically, this is just an automatically filled copy of the data, indexed by other fields.
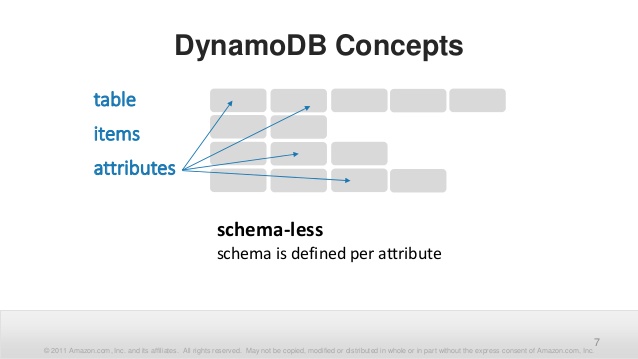
Among keys, Items hold attributes. Attributes have names — strings. (Keys, every part, also have their names.) And attributes have values. It's interesting.
You can store scalar values. Strings up to 400 kilobytes. Numbers, like in JavaScript, all numbers are decimals. You can atomically increment numbers (by the value specified in the update), so it's easy to create counters. Binary, just binary data, up to 400 kilobytes.
You can store sets of scalar values. You can add or remove elements from the set. You can store lists and maps. This way, you can even store JSON documents, however, the nesting level is limited to 32.
The full size of the Item is limited to those 400 kilobytes. Not like in Cassandra. Even less than document size in MongoDB. But within these 400 kilobytes, you can put any number of attributes.
Each Item in a Table may have its own set of attributes, not related to other Items.
When writing, you must define the primary key and attribute values. An upsert will be done, new attributes are added if absent, attributes are updated if they already exist. There are operations to modify numbers, sets, lists, and maps. So, it's possible to do partial updates.
There are two operations for reading: Scan and Query.
Scan is just a sequential scan of the whole Table, applying filters. Scan is not optimised and doesn't use indexes. So, it's not recommended to use it. But it exists.
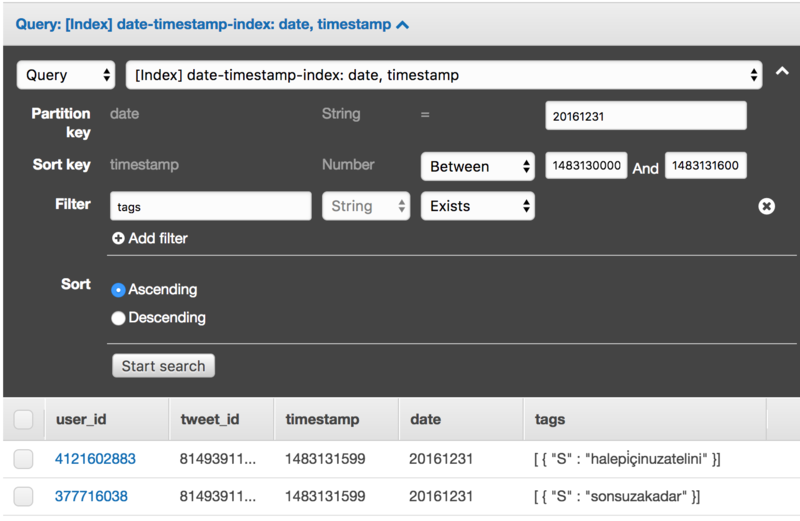
Query is a more sophisticated query. Concrete value for the partition key. A range for the sort key. It limits the scope of looked-up data. Sort order. Projection, you can define which attributes you want to extract. Filters, you can filter the resulting Items by attribute values. Equal, not equal, greater, less, exists, not exists, contains substring, starts with substring. There are many filters. But filters do not increase query performance, as the search is done only by keys. But they can save some bandwidth, as fewer data will be transferred.
It's easier to work with DynamoDB using SDKs. For Java, it has a good OOP API where you can create queries from objects. Java collections can be transparently stored as DynamoDB sets, lists, and maps. But at the lower level, it's an HTTP API. So, for the simplest cases, you may use any HTTP client.
A pretty complex query using SDK in Kotlin may look like this:
// QuerySpec is the SDK class to define the query
val querySpec = QuerySpec()
// hash key is `u` and we pass `:location` parameter here
// sort key is `t` and we're selecting items between `:start` and `:end`
.withKeyConditionExpression(
"u = :location AND t BETWEEN :start AND :end")
// sorting by the sort key in reverse order
.withScanIndexForward(false)
// each Item has some attributes with sensor values
// here we're declaring that we want to retrieve some attributes,
// but their exact names will be provided as `#attr1`, `#attr2`, ... parameters
.withProjectionExpression(sensors.mapIndexed { index, _ -> "#attr$index" }
.joinToString(", "))
// we want only Items where the sensor attributes exist,
// skipping Items without necessary data
.withFilterExpression(sensors.mapIndexed { index, _ -> "attribute_exists(#attr$index)" }
.joinToString(" OR "))
// we want 1000 Items max
.withMaxResultSize(1000)
// here we define the exact names for `#attr1`, `#arrt2`, ... parameters,
// they are taken from the `sensors` map
.withNameMap(sensors.mapIndexed { index, name -> "#attr$index" to name }.toMap())
// here we define exact values for `:location`, `:start` and `:end` parameters
.withValueMap(mapOf(
":location" to location,
":start" to Instant.parse("2018-04-20T00:00:00Z").epochSecond,
":end" to Instant.parse("2018-04-21T00:00:00Z").epochSecond
))
// actual execution of the query over the `table`
val items = table.query(querySpec)
// processing results
for (item in items) {
// ...
}
This syntax with key condition, projection, and filter expressions
is relatively new.
It allows to declare parameters
for values (starting with :)
and attribute names (starting with #).
Looks even too flexible,
but it allows to create generic code,
customizing the query to a specific set of attributes,
by the sensors map in this example.
Writes (actually, updates) may look simpler:
// define the key for the update
val key = PrimaryKey("u_period", hashKey, "t", rangeKey)
// define the list of updates, per each attribute
val updateOps = listOf(
// these updates increment numeric values
AttributeUpdate("${sensor}_count").addNumeric(aggregate.count),
AttributeUpdate("${sensor}_sum").addNumeric(aggregate.sum)
)
// executing the update of a single Item in the `table`
table.updateItem(key, *updateOps.toTypedArray())
Note, you can update only a single Item at once.
Also, you can add a condition expression to the update operation. So, it's possible to implement compare-and-set logic in DynamoDB, as the update with the condition expression check is performed atomically. This allows you to use DynamoDB for synchronisation in distributed systems.
Condition expression example:
try {
// trying to update a single Item
table.updateItem(key,
// incrementing a nested number inside map of the map
// by the `:inc` value.
// `#sensor` is the attribute of map type
// its `#state` key is also a map.
"SET #sensor.#state.#name = #sensor.#state.#name + :inc",
// condition expression checks that the maps and their keys exist
"attribute_exists(#sensor.#state.#name)",
// defining actual names for attribute and maps keys
mapOf("#sensor" to sensor, "#state" to state, "#name" to name),
// increment value, just one in this case
mapOf(":inc" to 1))
} catch (e: ConditionalCheckFailedException) {
// if the nested number does not exist (maps have no such keys),
// the exception is thrown
try {
// trying to create the initial number value,
// to be able to increment later
table.updateItem(key,
// just setting value to the nested number
"SET #sensor.#state.#name = :value",
// condition expression checks the attribute `#sensor`
// and the first map key `#state` exist
"attribute_exists(#sensor.#state)",
// defining actual names for attribute and maps keys
mapOf("#sensor" to sensor, "#state" to state, "#name" to name),
// initial value, just one for this case
mapOf(":value" to 1))
} catch (e: ConditionalCheckFailedException) {
// ...
}
}
You see,
if the condition expression evaluates to false,
the exception is thrown and the update is not performed.
You may catch the exception and execute another update.
The expression syntax allows you to reference
nested values,
a number in a map in a map attribute in this case,
using dot notation: #attribute.#mapkey1.#mapkey2.
You can do mostly anything with the DynamoDB data model. You just need to be careful with the partition key. There must be many unique values for your key to create a large enough number of partitions. And they should not be monotonically increasing values, like timestamps. First, you'll have to select every second (or whatever granularity you have) separately. Second, you'll get a "hot" partition when all writes go to the "today" partition.
Finally: performance and cost. In cloud DBs, they are tightly related.
You must pay. For "write request units", the number of write operations per second allowed. For "read request units", the number of read operations per second allowed. Where an "operation" is writing something up to 1 kilobyte, or reading something up to 4 kilobytes. Reading is much (ten or even forty times, if counting data size) cheaper than writing. You pay for stored data size per gigabyte. You pay for transferred data per gigabyte per month. Inbound (writes) are free. Outbound (reads) — not.
They can scale your Table automatically to provide on-demand capacity. But, as it is in the cloud, be careful, as unlimited scaling may cost you a lot in case of an unexpected spike in load.
Remember, performance is limited per each Table separately and is distributed between the partitions. The partition key is important again. And even the paid performance has limits. However, tens of thousands of units should be enough for everything.
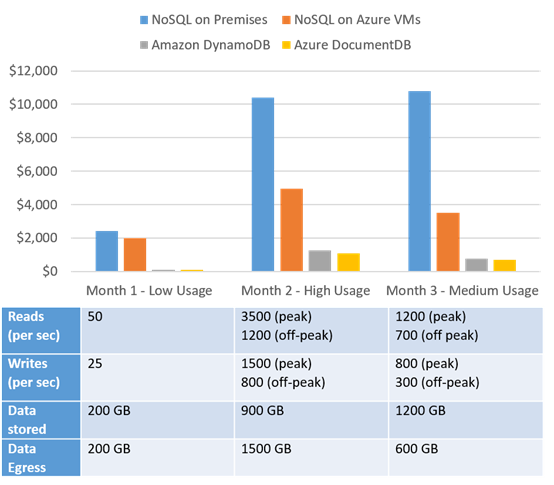
Also, you need to pay for replication (including across datacenters), for backups, for cache instances (yes, there are special caches), for DynamoDB Streams, and for triggers.
Streams allow you to re-play DB writes somewhere else. For example, pass them to Lambda functions and do something useful there.
Triggers in DynamoDB are also Lambda functions that receive write operations and may do anything in AWS, including writes into another DynamoDB Table. You need to pay for Lambda calls.
DynamoDB is well integrated into AWS infrastructure. You may transfer data from DynamoDB into Redshift. Or process DynamoDB tables with Apache Hadoop, making aggregation queries with HiveQL. (DynamoDB itself cannot do group-by queries.)
So, it is a good enough cloud NoSQL. And, if you are in AWS, and need to quickly store and access a large amount of data, try DynamoDB first. Probably, it'll be enough. If not, you may load data from DynamoDB into something more powerful.
Or, the opposite scenario is also valid. If you need to easily store a couple of flags, counters, or small documents to be used by your Lambda functions, check DynamoDB first. It may cost you much less than even the smallest RDS instance.